🔥 [2025-01-28]: We added analysis on LLM-as-a-Judge and o1-like Reasoning Enhancement, as well as meta-evaluation results on o1-mini, Gemini-2.0-Flash-Thinking-1219, and DeepSeek-R1!
🌟 [2025-01-16]: We shared and discussed the methodologies, applications (Finance, RAG, and Synthetic Data), and future research directions of LLM-as-a-Judge at BAAI Talk! 🤗
[Replay]
[Methodology]
[RAG & Synthetic Data]
🚀 [2024-11-23]: WWe released A Survey on LLM-as-a-Judge, exploring LLMs as reliable, scalable evaluators and outlining key challenges and future directions!
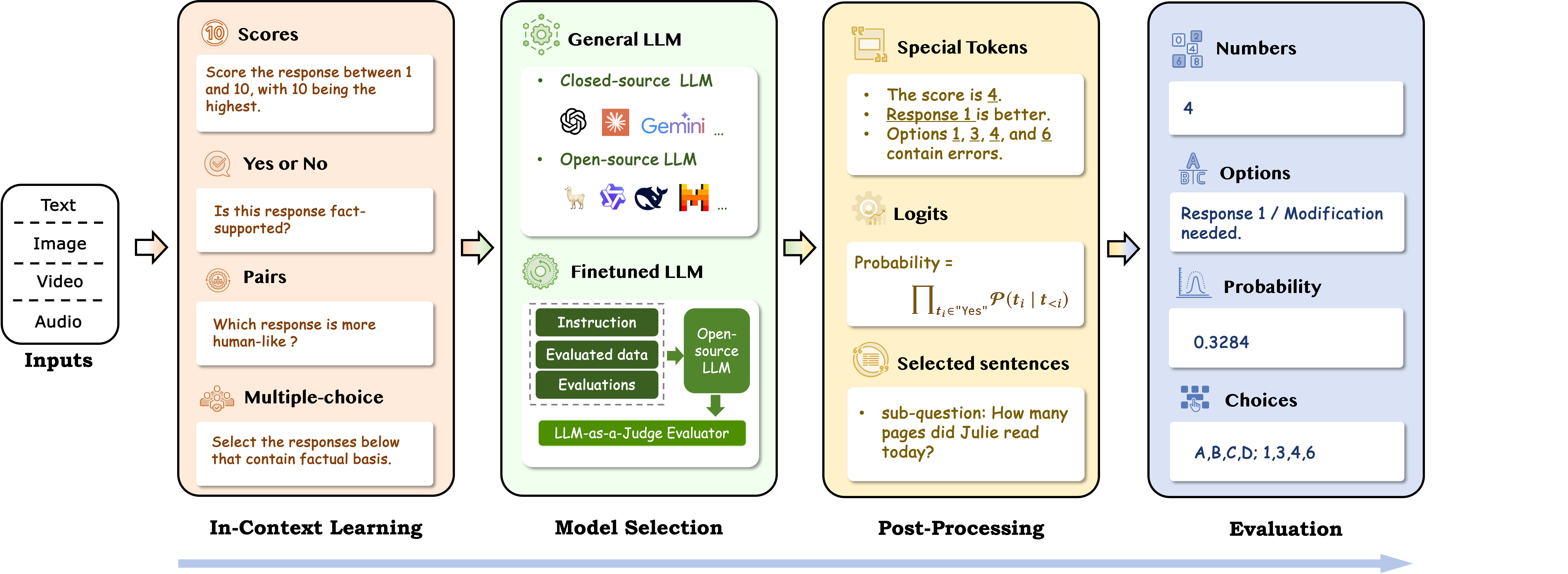
Accurate and consistent evaluation is crucial for decision-making across numerous fields, yet it remains a challenging task due to inherent subjectivity, variability, and scale. Large Language Models (LLMs) have achieved remarkable success across diverse domains, leading to the emergence of "LLM-as-a-Judge," where LLMs are employed as evaluators for complex tasks. With their ability to process diverse data types and provide scalable and flexible assessments, LLMs present a compelling alternative to traditional expert-driven evaluations.
However, ensuring the reliability of LLM-as-a-Judge systems remains a significant challenge that requires careful design and standardization. This paper provides a comprehensive survey on LLM-as-a-Judge, offering a formal definition and a detailed classification, while focusing on addressing the core question: How to build reliable LLM-as-a-Judge systems? We explore strategies to enhance reliability, including improving consistency, mitigating biases, and adapting to diverse assessment scenarios. Additionally, we propose methodologies for evaluating the reliability of LLM-as-a-Judge systems, supported by a novel benchmark designed for this purpose. To advance the development and real-world deployment of LLM-as-a-Judge systems, we also discussed practical applications, challenges, and future directions. This survey serves as a foundational reference for researchers and practitioners in this rapidly evolving field.
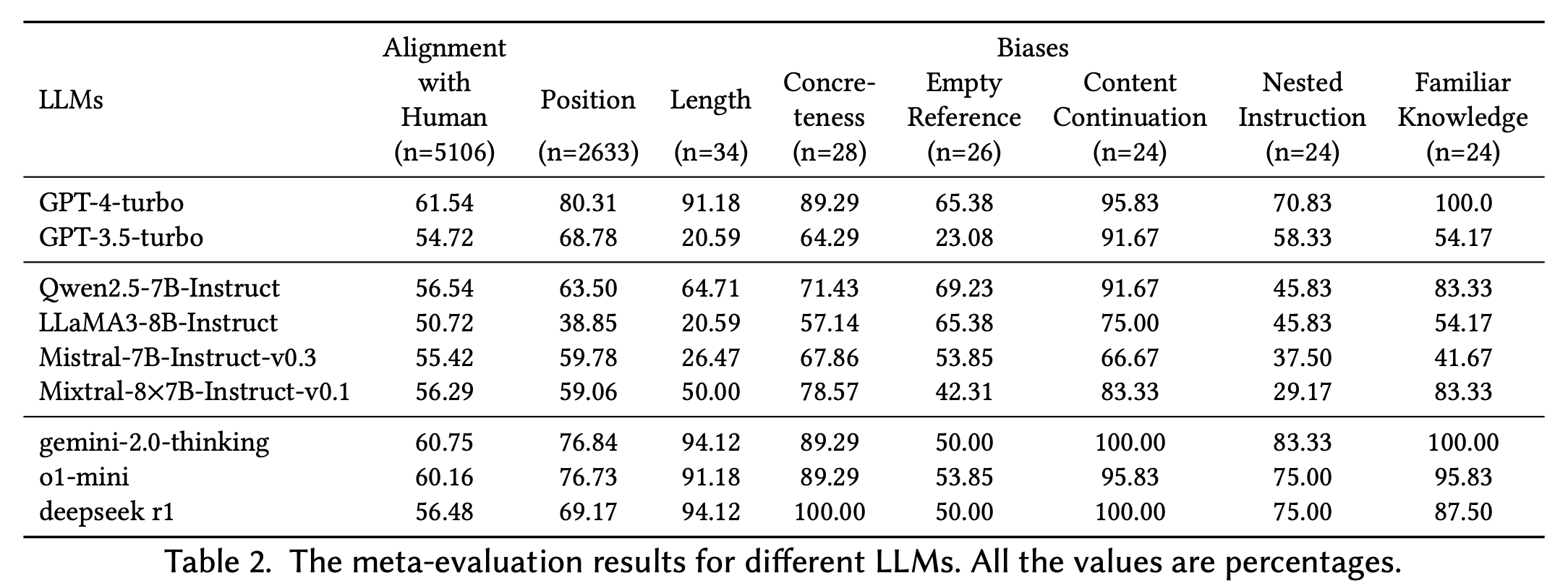
We also conducted a meta-evaluation of improvement strategies for LLM-as-a-Judge systems using benchmarks such as LLMEval2 and EVALBIASBENCH to assess their effectiveness in optimizing evaluation performance and mitigating biases. Notably, we analyzed the performance of reasoning-enhanced LLMs, demonstrating their advancements over baseline models but highlighting their inconsistent improvements in alignment-related tasks.

@article{gu2024survey,
title={A Survey on LLM-as-a-Judge},
author={Gu, Jiawei and Jiang, Xuhui and Shi, Zhichao and Tan, Hexiang and Zhai, Xuehao and Xu, Chengjin and Li, Wei and Shen, Yinghan and Ma, Shengjie and Liu, Honghao and others},
journal={arXiv preprint arXiv:2411.15594},
year={2024}
}